




Country contagion curves: seven-day predictions based on consolidated data for May 17, 2020 – source: Websensors (image: Websensors)
Digital tool developed at the University of São Paulo’s Mathematics and Computer Sciences Institute (ICMC-USP) in São Carlos refines projections for the spread of the pandemic.
Digital tool developed at the University of São Paulo’s Mathematics and Computer Sciences Institute (ICMC-USP) in São Carlos refines projections for the spread of the pandemic.
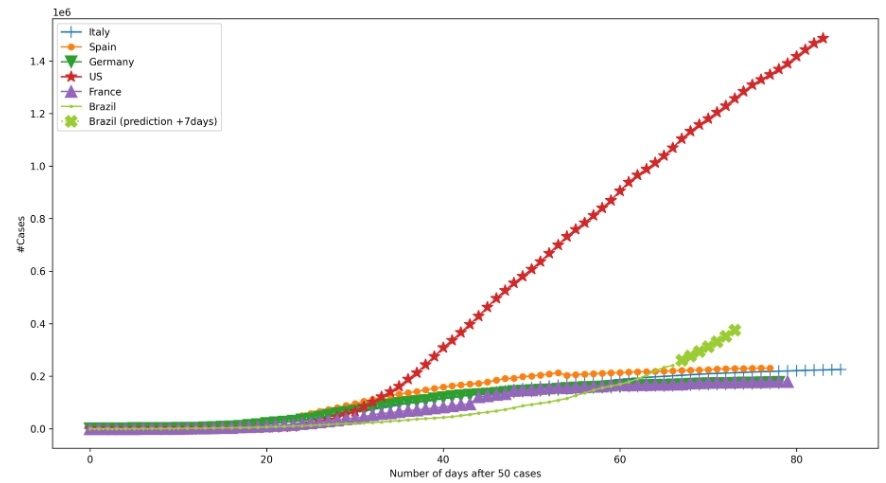
Country contagion curves: seven-day predictions based on consolidated data for May 17, 2020 – source: Websensors (image: Websensors)
By José Tadeu Arantes | Agência FAPESP – A data and text mining tool called Websensors is being used to analyze the progression of the COVID-19 pandemic. By extracting data from news stories to obtain information on what happened, when and where, Websensors enables analysts to adjust propagation models on a daily basis.
The tool was developed at the University of São Paulo’s Mathematics and Computer Sciences Institute (ICMC-USP) in São Carlos (state of São Paulo, Brazil) by researchers Solange Rezende, Ricardo Marcacini and Rafael Rossi, with Roberta Sinoara also participating. It was supported by FAPESP via the project “Machine learning for Websensors: algorithms and applications” and doctoral scholarships awarded to Marcacini, Rossi and Sinoara, all of whom were supervised at the time by Rezende.
The instance of Websensors dedicated to the COVID-19 pandemic is available at websensors.net.br/projects/covid19/, with a web interface developed by Luan Martins, a master’s student at ICMC-USP.
“We apply data mining to news articles as a way of identifying events that are occurring in each country and adjust projections for Brazil,” Rezende told Agência FAPESP.
The main focus for research relating to Websensors, she added, is whether predictive models can be adjusted on the basis of supplementary data extracted from news stories.
“The tool uses a five-stage mining methodology. The stages are identification of the problem, pre-processing, pattern extraction, post-processing, and knowledge use,” Marcacini said.
Identifying the problem means defining the scope of the application and the data sources. Daily data on the global spread of the pandemic are collected from the COVID-19 Data Repository run by the Center for Systems Science and Engineering (CSSE) at Johns Hopkins University, Rezende explained.
News articles in more than 100 languages are obtained from the GDELT Project. “This large, highly selective platform protects us against fake news,” she said.
Pre-processing uses algorithms that convert news reports into events. “We want only news articles in which we can identify what happened, when and where, with georeferencing. When at least these three types of information can be extracted from an article, we have an event that can be analyzed by a computer program,” Marcacini said.
Pattern extraction involves a neural network fed with contagion curves for several countries, enriched by the addition of pre-processed events from the previous stage. “For the output, we’ve configured the neural network to return to the contagion curve and take Brazil’s characteristics into consideration,” Marcacini said.
Post-processing entails evaluating the model. “Different evaluation techniques can be deployed,” Rezende said. “In one technique, the model is used to predict some of the data we know, so we can quantify the hits and misses.”
Knowledge use means making the data available to other researchers and systems. In this case, all the knowledge obtained about the pandemic can be freely accessed at websensors.net.br/projects/covid19/.
According to Rezende, the Websensors platform has published daily updates to its seven-day predictions for the contagion curve in Brazil using the event-adjusted model. The data are available to anyone interested. However, she warned that the tool is still being fine-tuned. “It’s important to stress that Websensors wasn’t built for this purpose. Nevertheless, we believe we can use what’s available to collaborate in these hard times,” she said.
The Agency FAPESP licenses news via Creative Commons (CC-BY-NC-ND) so that they can be republished free of charge and in a simple way by other digital or printed vehicles. Agência FAPESP must be credited as the source of the content being republished and the name of the reporter (if any) must be attributed. Using the HMTL button below allows compliance with these rules, detailed in Digital Republishing Policy FAPESP.
